

Dane badawcze
Love Data Week 2026
UWAGA!
Na platformie Navoica znajdują się przeznaczone dla naukowców kursy z zakresu zarządzania danymi badawczymi opracowanych w ramach zadania realizowanego przez Narodowe Centrum Nauki na podstawie zlecenia Ministra Edukacji i Nauki dotyczącego krajowej koordynacji partnerstwa European Open Science Cloud w latach 2022-2023.
Kursy zostały przygotowane odpowiednio na poziomie podstawowym oraz średniozaawansowanym.
Dane badawcze to „informacje sektora publicznego utrwalone w postaci elektronicznej, inne niż publikacje naukowe, które zostały wytworzone lub zgromadzone w ramach działalności naukowej* i są wykorzystywane jako dowody w procesie badawczym lub służą do weryfikacji poprawności ustaleń i wyników badań” (art. 2 pkt 2 ustawy z dnia 11 sierpnia 2021 r. o otwartych danych i ponownym wykorzystaniu informacji sektora publicznego, Dz. U. 2021 poz. 1641).
* w rozumieniu art. 4 ustawy z dnia 20 lipca 2018 r. – Prawo o szkolnictwie wyższym i nauce, Dz. U. z 2023 r. poz. 742 i 1088
Danymi badawczymi określamy zarówno dane surowe (uzyskane bezpośrednio z zastosowania narzędzia badawczego), jak i dane przetworzone (przygotowane do analizy i stanowiące podstawę dla dochodzenia do konkluzji badawczych).
Dane badawcze mogą przyjmować różnorodną formę zależną od dyscypliny naukowej i charakteru przeprowadzanych badań. Mogą być to m.in. dane liczbowe i tekstowe, kwestionariusze i wyniki badań ankietowych, nagrania audio i wideo, obrazy czy oprogramowanie.
Cykl życia danych
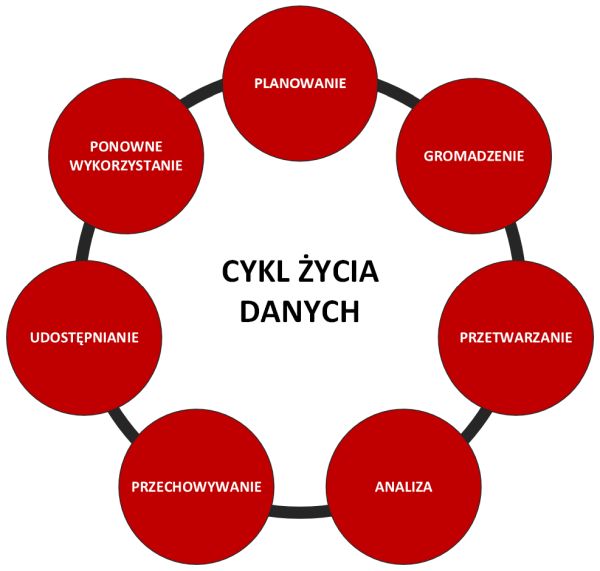
Dane badawcze mają zwykle trwałość wykraczającą poza trwałość projektu, na potrzeby którego są gromadzone, przetwarzane i analizowane. Odpowiednio przygotowane dane mogą z powodzeniem zostać ponownie wykorzystane w formie niezmienionej bądź uzupełnione o inne dane - i tym samym znów stanowić podstawę dla prowadzenia kolejnych badań. W takiej sytuacji mogą one zostać ponownie wykorzystanie nie tylko przez osoby odpowiadające za ich gromadzenie, przetwarzanie i analizę, ale także przez badaczy z zewnątrz. Podobny obieg danych w działalności naukowej można przedstawić graficznie jako tzw. cykl życia danych.
Zarządzanie danymi badawczymi
Wszystkie działania związane z organizacją, przechowywaniem i udostępnianiem danych badawczych dla zapewnienia możliwości ich odnalezienia, dostępności, interoperacyjności i możliwości ponownego wykorzystania zbiorczo określane są jako zarządzanie danymi badawczymi (Research Data Management, RDM).
Plany zarządzania danymi
Zarządzanie danymi badawczymi jest dobrą praktyką w prowadzeniu badań naukowych, a jego zastosowanie pomaga w realizowaniu badań w sposób bardziej wydajny, skuteczny i uporządkowany. Co jednak ważniejsze, znacząca część instytucji finansujących badania naukowe wymaga zastosowania praktyk związanych z zarządzaniem danymi badawczymi i opisania ich na etapie wnioskowania o środki w postaci oddzielnego dokumentu, który nazywamy planem zarządzania danymi (Data Management Plan, DMP).
Podstawowe informacje zawarte w DMP różnią się w zależności od wymogów instytucji finansującej badania, dyscypliny naukowej i przyjętej metodologii, generalnie jednak powinien on opisywać (na podstawie Science Europe: Practical guide to The International Alignment of Research Data Management: extended edition with DMP evaluation rubric [online]. 2021. Dostępne w: doi:10.5281/ZENODO.4915861):
- opis danych oraz ich gromadzenia lub procedura pozyskania danych już istniejących (np. jakie dane gromadzimy? w jaki je sposób gromadzimy? skąd i jaki gotowy zestaw danych pobieramy? dane w jakich formatach będą przez nas gromadzone lub przetwarzane? jaki będzie ich rozmiar?),
- dokumentacja i zapewnienie jakości danych (np. w jaki sposób opisujemy dane? jaki będziemy stosować standard metadanych? jaka dokumentacja będzie wytwarzana podczas prowadzenia badań? w jaki sposób dane będą uporządkowane [konwencje nazewnicze, wersjonowanie, struktura folderów]?)
- przechowywanie i kopie zapasowe (gdzie dane będą przechowywane? jak często będą przygotowywane kopie zapasowe? czy będą przygotowywane automatycznie? czy zastosowana zostanie zasada 3-2-1? kto będzie miał dostęp do danych? w jaki sposób dane będą odzyskiwane w razie incydentów?)
- wymogi prawne i etyczne (czy będą gromadzone dane osobowe? jakie zgody będą pozyskiwane? czy dane będą anonimizowane? czy dane będą pseudonimizowane? jakie będą procedury udzielania dostępu do danych? kto będzie nimi nadzorował? jak stosowane będą prawa zarządzania własnością intelektualną? czy podpisywane były umowy na wykorzystanie danych zewnętrznych?
- udostępnianie i archiwizacja danych (w jaki sposób metadane i dane będą udostępniane? od kiedy będą dostępne? z użyciem jakiej licencji będą udostępniane i w jakim repozytorium? czy repozytorium spełnia zasady FAIR? jak długo dane będą udostępniane? dlaczego dane nie mogą być udostępnione? które dane zostaną wybrane do udostępnienia i dlaczego? która wersja danych będzie udostępniona? jakie oprogramowanie lub narzędzia będą niezbędne do tego, aby uzyskać dostęp do danych?)
- odpowiedzialność za zarządzanie danymi (kto jest odpowiedzialny za zarządzanie i/lub opiekę nad danymi? kto nadzoruje nad realizacją założeń przedstawionych w DMP? jakie ponoszone będą na ten cel nakłady?)
W serwisie internetowym NCN zamieszczone są zbieżne z rekomendacjami Science Europe wytyczne dotyczące informacji, jakie powinny znaleźć się w przygotowanym przez wnioskodawcę DMP.
Przykłady gotowych DMP:
- Przykłady z Data Curation Centre
- Przykład opracowany przez Daniela Gackowiego z Collegium Medicum UMK i Bożenę Bednarek-Michalską z UMK
Grantodawcy
Część instytucji finansujących badania naukowe wymaga przygotowania DMP na etapie wnioskowania o środki na potrzeby realizacji grantu oraz jego aktualizowanie podczas trwania projektu. Wśród znaczących grantodawców wymagających tworzenia podobnych dokumentów możemy wskazać m.in.:
- National Institute of Health
- Wellcome Trust
- Komisja Europejska (Horizon Europe)
- Medical Research Council
- Narodowe Centrum Nauki (NCN)
Narzędzia
Tworzenie i aktualizowanie planów zarządzania danymi:
- DMPTool (US), DMPonline (UK), Argos (UE) i Data Stewardship Wizard – narzędzia przygotowujące szablony i umożliwiające udostępnianie oraz eksportowanie DMP dostosowanych do wymagań amerykańskich i europejskich grantodawców.
- Checklist for a Data Management Plan – lista kontrolna ułatwiająca identyfikację brakujących informacji w DMP.
Narzędzie do sprawdzenia zgodności czasopisma z wymogami instytucji finansującej badania:
Narzędzia do anonimizacji danych:
Narzędzia do czyszczenia danych:
Metadane
Metadane to zestaw informacji opisujących obiekt, określany często jako „dane o danych”. W zależności od rodzaju opisywanego obiektu możemy wyróżnić metadane deskryptywne (np. tytuł, abstrakt, słowa kluczowe etc.), strukturalne (wersja, seria, elementem jakiego zbioru jest dany obiekt etc.) i administracyjne (data, typ zasobu, licencja etc.).
Schematy metadanych
Dobrą praktyką jest opisywanie danych metadanymi posiadającymi jasną strukturę, określone wartości pól oraz spójną formę. Do realizacji tej praktyki zaleca się stosowanie schematów metadanych.
Schemat metadanych określa zakres elementów opisujących obiekt oraz zasady, zgodnie z którymi elementy te mają być uzupełnione.
Wykorzystanie konkretnego schematu metadanych sprawia, że opisane nim obiekty stają się możliwe do znalezienia i wzajemnie porównywalne, a sam opis (ze względu na jednoznaczność poszczególnych elementów opisu) może zostać odczytany maszynowo.
Repozytoria danych mogą wymagać zastosowania konkretnych schematów metadanych dla deponowanych obiektów – w takim przypadku zasady uzupełnienia poszczególnych pól z informacjami o obiekcie można znaleźć bezpośrednio w formularzu deponowania danych badawczych.
Schematy metadanych można znaleźć korzystając z serwisów:
- FAIRsharing – serwis internetowy rejestrujący standardy, bazy danych i polityki udostępniania danych.
- Metadata Standards Catalog – serwis rejestrujący schematy metadanych stosowanych dla danych badawczych.
Przykłady schematów ogólnego przeznaczenia
- Dublin Core – ogólny standard metadanych przyjęty jako ISO 15836-2003.
- DataCite Metadata Schema – ogólny standard metadanych umożliwiający identyfikację zasobu na potrzeby jego cytowania i wyszukiwania.
- DDI (Data Documentation Initiative) – ogólny standard metadanych służący do opisu danych uzyskanych z ankiet i innych metod obserwacyjnych, zwłaszcza z zakresu nauk społecznych i nauk o zdrowiu.
Przykłady schematów dziedzinowych
- ISA-Tab – schemat metadanych stosowany do opisu danych będących wynikiem przeprowadzania eksperymentu.
- Protocol Data Element Definitions – schemat metadanych służący do opisu prób klinicznych rejestrowanych w serwisie ClinicalTrials.gov.
- PDBx/mmCIF – schemat metadanych stosowanych w danych deponowanych w serwisie Protein Data Bank.
- Genome Metadata – schemat metadanych służący do przypisywania dodatkowych informacji do genomu wykraczających poza jego sekwencjonowanie i adnotację.
- Darwin Core – schemat metadanych stosowany do udostępniania informacji dotyczącej bioróżnorodności.
Archiwizacja i udostępnianie danych badawczych
Archiwizacja danych badawczych
Kluczową praktyką skutecznego zarządzania danymi badawczymi jest stosowanie długoterminowych strategii ich przechowywania, ochrony i finalnie, o ile jest to możliwe, udostępniania.
Archiwizacja to zapewnienie dla danych przestrzeni w lokalizacjach sieciowych administrowanych przez uczelnię (np. serwer uczelniany) lub lokalizacjach zewnętrznych (np. repozytorium danych) i służy głównie zabezpieczeniu danych przed ich utratą.
Nie wszystkie gromadzone i przetwarzane dane badawcze należy archiwizować. Z reguły instytucja finansująca badania powinna określić, jaki zakres danych powinien podlegać archiwizacji. Jeśli nie dysponujemy podobnymi informacjami, to do archiwizacji należy wybrać dane, które:
- będą wykorzystywane w przygotowaniu wyników badań do publikacji,
- mają wysoką wartość naukową,
- mogą zostać ponownie wykorzystane przez samych autorów,
- nie mogą być reprodukowane lub ich ponowienie jest kosztowne.
Jedną z zalecanych zasad archiwizacji danych jest tzw. reguła 3-2-1, zgodnie z którą należy tworzyć trzy kopie zapasowe przetrzymywane na dwóch odrębnych nośnikach oraz jedną kopię przechowywaną w lokalizacji zewnętrznej.
Więcej informacji można uzyskać z publikacji: Selekcja i przygotowanie danych badawczych do udostępnienia.
Otwieranie danych badawczych
Zgodnie z art. 2 pkt 11 ustawy z dnia 11 sierpnia 2021 r. o otwartych danych i ponownym wykorzystaniu informacji sektora publicznego otwarte dane to „informacje sektora publicznego udostępniane lub przekazywane w postaci elektronicznej, bezwarunkowo lub z uwzględnieniem warunków, o których mowa w rozdziale 3, kompletne, aktualne, w wersji źródłowej, w otwartym i niezastrzeżonym formacie przeznaczonym do odczytu maszynowego, które są przeznaczone do bezpłatnego ponownego wykorzystywania na tych samych zasadach dla każdego użytkownika, bez konieczności potwierdzania tożsamości przez użytkownika” oraz zgodnie z art. 22 ww. ustawy dane badawcze „podlegają bezpłatnie ponownemu wykorzystaniu, jeżeli zostały wytworzone lub zgromadzone w ramach działalności naukowej finansowanej ze środków publicznych oraz są już publicznie udostępniane w systemie teleinformatycznym podmiotu zobowiązanego, w szczególności w repozytorium instytucjonalnym lub tematycznym. Podmiot zobowiązany, udostępniając te dane, wraz z ich udostępnieniem informuje o braku warunków ponownego wykorzystywania albo określa te warunki”.
Dalsze informacje i wytyczne dotyczące otwartego dostępu do danych badawczych zostaną opisane w dokumencie Polityka otwartego dostępu do danych badawczych finansowanych ze środków publicznych wydawanym przez Ministra właściwego ds. Edukacji i Nauki.
Więcej informacji można uzyskać z publikacji: Prawne aspekty otwierania danych badawczych – poradnik.
Udostępnianie danych badawczych
Jednym z głównych celów zarządzania danymi badawczymi jest ich otwieranie i udostępnianie dla szerokiego grona odbiorców. Podobne działania służą m.in.:
- ponownemu wykorzystaniu danych,
- weryfikacji badań,
- zwiększeniu widoczności naukowców,
- zwiększenie cytowalności publikacji powiązanych z zestawem danych.
Z założenia dane powinny być „tak otwarte, jak to możliwe – i tak zamknięte, jak to konieczne” (as open as possible, as closed as necessary).
Archiwizacja i udostępnianie danych zwykle realizowane są w ramach tej samej infrastruktury – czyli w repozytoriach danych, które specjalizują się w ich indeksowaniu i długoterminowym przechowywaniu. Repozytoria danych możemy podzielić na repozytoria:
- ogólnego przeznaczenia (sieroce) (gromadzą wszystkie rodzaje danych badawczych),
- instytucjonalne (ograniczają się do danych tworzonych w ramach funkcjonowaniu instytucji),
- dziedzinowe (związane z konkretną dziedziną lub dyscypliną naukową).
Więcej informacji można uzyskać w publikacji: Jak korzystać z zasobów w repozytoriach danych.
Portale danych
- dane.gov.pl – oficjalny portal polskich danych prowadzony przez ministra właściwego do spraw informatyzacji, będący m.in. centralnym repozytorium danych udostępnianych przez polską administrację publiczną, w tym Narodowy Fundusz Zdrowia.
- data.europa.eu - oficjalny portal europejskich danych, służący do rejestrowania i udostępniania danych generowanych m.in. przez instytucje publiczne działające na terenie UE.
Rejestry repozytoriów danych
Przy poszukiwaniu repozytorium danych przede wszystkim musimy dostosować się do wymogów agencji finansującej badania lub wytycznych wydawcy, u którego planujemy opublikować wyniki badań. Jeśli podobne wymogi wraz z konkretnymi propozycjami repozytoriów nie istnieją (np. Narodowe Centrum Nauki nie określa skończonej listy preferowanych repozytoriów), dane najlepiej deponować w repozytorium dziedzinowym albo w repozytorium instytucjonalnym.
W doborze repozytorium nieocenione mogą okazać się doświadczenia i dobre praktyki stosowane przez współpracowników.
W wyszukiwaniu repozytoriów danych warto korzystać z ich rejestrów:
- re3data – najobszerniejszy baza repozytoriów danych badawczych, pozwalający na ich wyszukiwanie oraz przeglądanie z podziałem na rejestrowane dziedziny i dyscypliny naukowe.
- NIH Data Sharing Resources – lista wykazująca repozytoria danych wspierane przez amerykański National Institute of Health.
- OpenDOAR – baza indeksująca biblioteki cyfrowe, repozytoria instytucjonalne oraz repozytoria danych badawczych.
Przykładowe repozytoria danych
I. Repozytoria ogólnego przeznaczenia
- Mendeley Data i Figshare – darmowe repozytoria danych badawczych ogólnego przeznaczenia.
- Most Danych – repozytorium opracowane przez Politechnikę Gdańską, Uniwersytet Gdański oraz Gdański Uniwersytet Medyczny archiwizujące i udostępniające dane badawcze. W 2023 roku uzyskało certyfikację Core Trust Seal.
- RepOD – repozytorium Otwartych Danych opracowane przez ICM UW w ramach działań Platformy Otwartej Nauki archiwizujące i udostępniające wszystkie dane opracowywane w ramach działań naukowych.
- Repozytorium PPM – repozytorium otwartych danych badawczych Polskiej Platformy Medycznej.
- Repozytoria danych badawczych NIH – rejestr polecanych amerykański National Institute of Health repozytoriów danych dziedzinowych i ogólnego przeznaczenia.
II. Repozytoria dziedzinowe
- GenBank – repozytorium gromadzące informacje o genowych sekwencjach nukleotydowych.
- Protein Data Bank – repozytorium gromadzące dane o strukturze przestrzennej białek i kwasów nukleionowych.
III. Repozytorium instytucjonalne Pomorskiego Uniwersytetu Medycznego w Szczecinie
Zasady FAIR
Część agencji finansujących badania naukowe wymagających udostępniania danych badawczych (m.in. Komisja Europejska i Narodowe Centrum Nauki) oczekuje, że będą one spełniać tzw. zasady FAIR – czyli będą możliwe do znalezienia (Findable), dostępne (Accessible), interoperacyjne (Interoperable) i nadające się do ponownego wykorzystania (Reusable). Dane spełniające zasady FAIR są optymalnie przygotowane do udostępnienia poprzez spełnienie szeregu kryteriów:
- Findable (możliwe do znalezienia):
- (Meta)dane mają przypisany unikalny i trwały identyfikator,
- dane są opisane z użyciem wyczerpujących metadanych,
- (meta)dane są zarejestrowane i indeksowane w przeszukiwalnych źródłach.
- Accessible (dostępne):
- (Meta)dane można pozyskać poprzez ich identyfikator z wykorzystaniem standardowego protokołu komunikacyjnego,
- protokół jest otwarty, darmowy i możliwy do wdrożenia,
- jeśli jest taka konieczność, protokół umożliwia wprowadzenie autoryzacji,
- Metadane są dostępne nawet, gdy dostęp do danych nie jest już możliwy.
- (Meta)dane można pozyskać poprzez ich identyfikator z wykorzystaniem standardowego protokołu komunikacyjnego,
- Interoperable (interoperacyjne):
- (Meta)dane używają formalnego, dostępnego, udostępnianego i szeroko stosowanego języka reprezentacji wiedzy,
- (meta)dane używają słowników kontrolowanych,
- (meta)dane tworzą relację z innymi (meta)danymi.
- Reusable (nadające się do ponownego wykorzystania):
- (Meta)dane są opisywane z użyciem wyczerpujących, różnorodnych i kontekstowych atrybutów.
- (meta)dane są udostępnione na jasnych i dostępnych licencjach,
- (meta)dane są powiązane z informacjami o ich pochodzeniu,
- (meta)dane spełniają standardy społeczności właściwe dla dziedziny wiedzy, do której przynależą.
- (Meta)dane są opisywane z użyciem wyczerpujących, różnorodnych i kontekstowych atrybutów.
Zasady FAIR są kluczowe dla współtworzenia i rozwijania serwisów pozwalających na wyszukiwanie, analizowanie i ponowne wykorzystanie wielu zestawów danych badawczych.
Repozytoria danych badawczych, poprzez konstrukcję odpowiednich schematów metadanych i formularzy dla udostępnianych metadanych mają duży wpływ na globalne realizowanie zasad FAIR. Warto zwrócić uwagę na działania grupy repozytoriów danych badawczych ogólnego przeznaczenia (Generalist Repository Ecosystem Initiative, GREI), która rozpoczęła współpracę w celu pełnego realizowania zasad FAIR, stworzenia spójnego schematu metadanych opisujących gromadzone w nich obiekty oraz podejmowania działań na rzecz edukowania naukowców z zakresu zarządzania danymi badawczymi.
Więcej informacji na temat zasad FAIR i wprowadzania ich do gromadzonych i udostępnianych przez siebie danych można znaleźć w serwisie How to FAIR.
Cytowanie danych
Na zestawy danych badawczych należy się powoływać tak samo, jak na publikacje naukowe.
W standardowym opisie bibliograficznym danych badawczych należy zawrzeć informacje o twórcy, roku utworzenia danych, tytule i trwałym identyfikatorze. Dodatkowo (jeśli dotyczy) można zamieścić m.in. informacje o wersji zestawu danych oraz o repozytorium, w którym dane są udostępnione.
Przykładowe opisy bibliograficzne dla danych badawczych:
- Vancouver
Haznedar B. Microarray Gene Expression Cancer Data [dataset]. Mendeley; 2017. Dostępny w: https://doi.org/10.17632/ynp2tst2hh.4
- APA
Haznedar, B. (2017). Microarray Gene Expression Cancer Data [dataset]. Mendeley. https://doi.org/10.17632/ynp2tst2hh.4
- AMA
Haznedar B. Microarray Gene Expression Cancer Data. 2017. doi:10.17632/ynp2tst2hh.4
Dane badawcze - kontakt w PUM
Specjalista do spraw danych badawczych i Otwartej Nauki
mgr Tomasz Nowocień
tel. +48 91-441-4450
e-mail: tomasz.nowocien@pum.edu.pl
